What Is PL/SQL?
PL SQL basically stands for "Procedural Language extensions to SQL". This is the extension of Structured Query Language (SQL) that is used in Oracle. Unlike SQL, PL/SQL allows the programmer to write code in procedural format.
It combines the data manipulation power of SQL with the processing power of procedural language to create a super powerful SQL queries.
It allows the programmers to instruct the compiler 'what to do' through SQL and 'how to do' through its procedural way.
Similar to other database languages, it gives more control to the programmers by the use of loops, conditions and object oriented concepts.
Architecture of PL/SQL
The PL/SQL architecture mainly consists of following 3 components:
- PL/SQL block
- PL/SQL Engine
- Database Server
PL/SQL block:
- This is the component which has the actual PL/SQL code.
- This consists of different sections to divide the code logically (declarative section for declaring purpose, execution section for processing statements, exception handling section for handling errors)
- It also contains the SQL instruction that used to interact with the database server.
- All the PL/SQL units are treated as PL/SQL blocks, and this is the starting stage of the architecture which serves as the primary input.
- Following are the different type of PL/SQL units.
- Anonymous Block
- Function
- Library
- Procedure
- Package Body
- Package Specification
- Trigger
- Type
- Type Body
PL/SQL Engine
- PL/SQL engine is the component where the actual processing of the codes takes place.
- PL/SQL engine separates PL/SQL units and SQL part in the input (as shown in the image below).
- The separated PL/SQL units will be handled with the PL/SQL engine itself.
- The SQL part will be sent to database server where the actual interaction with database takes place.
- It can be installed in both database server and in the application server.
Database Server:
- This is the most important component of Pl/SQL unit which stores the data.
- The PL/SQL engine uses the SQL from PL/SQL units to interact with the database server.
- It consists of SQL executor which actually parses the input SQL statements and execute the same.
Below is the pictorial representation of Architecture of PL/SQL.

Advantage of Using PL/SQL
- Better performance, as sql is executed in bulk rather than a single statement
- High Productivity
- Tight integration with SQL
- Full Portability
- Tight Security
- Support Object Oriented Programming concepts.
Basic Difference between SQL and PL/SQL
In this section, we will discuss some differences between SQL and PL/SQL
What is PL/SQL block?
PL/SQL is the procedural approach to SQL in which a direct instruction is given to the PL/SQL engine about how to perform actions like storing/fetching/processing data. These instruction are grouped together called Blocks.
Blocks contain both PL/SQL as well as SQL instruction. All these instruction will be executed as a whole rather than executing a single instruction at a time.
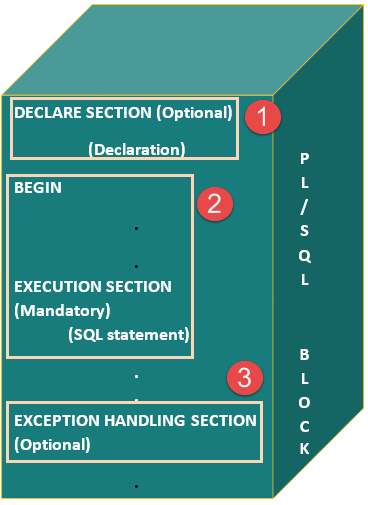
Block Structure
PL/SQL blocks have a pre-defined structure in which the code is to be grouped. Below are different sections of PL/SQL blocks
- Declaration section
- Execution section
- Exception-Handling section
The below picture illustrates the different PL/SQL block and their section order.
Declaration Section
This is the first section of the PL/SQL blocks. This section is an optional part. This is the section in which the declaration of variables, cursors, exceptions, subprograms, pragma instructions and collections that are needed in the block will be declared. Below are few more characteristics of this part.
- This particular section is optional and can be skipped if no declarations are needed.
- This should be the first section in a PL/SQL block, if present.
- This section starts with the keyword 'DECLARE' for triggers and anonymous block. For other subprograms this keyword will not be present, instead the part after the subprogram name definition marks the declaration section.
- This section should be always followed by execution section.
Execution Section
Execution part is the main and mandatory part which actually executes the code that is written inside it. Since the PL/SQL expects the executable statements from this block this cannot be an empty block, i.e., it should have at least one valid executable code line in it. Below are few more characteristics of this part.
- This can contain one or many blocks inside it as a nested blocks.
- This section starts with the keyword 'BEGIN'.
- This section should be followed either by 'END' or Exception-Handling section (if present)
Exception-Handling Section:
The exception are unavoidable in the program which occurs at run-time and to handle this Oracle has provided an Exception-handling section in blocks. This section can also contain PL/SQL statements. This is an optional section of the PL/SQL blocks.
- This is the section where the exception raised in the execution block is handled.
- This section is the last part of the PL/SQL block.
- Control from this section can never return to the execution block.
- This section starts with the keyword 'EXCEPTION'.
- This section should be always followed by the keyword 'END'.
The Keyword 'END' marks the end of PL/SQL block. Below is the syntax of the PL/SQL block structure.

Note: A block should be always followed by '/' which sends the information to the compiler about the end of the block.
Types of PL/SQL block
PL/SQL blocks are of mainly two types.
- Anonymous blocks
- Named Blocks
Anonymous blocks:
Anonymous blocks are PL/SQL blocks which do not have any names assigned to them. They need to be created and used in the same session because they will not be stored in the server as a database objects.
Since they need not to store in the database, they need no compilation steps. They are written and executed directly, and compilation and execution happen in a single process.
Below are few more characteristics of Anonymous blocks.
- These blocks don't have any reference name specified for them.
- These blocks start with the keyword 'DECLARE' or 'BEGIN'.
- Since these blocks are not having any reference name, these cannot be stored for later purpose. They shall be created and executed in the same session.
- They can call the other named blocks, but call to anonymous block is not possible as it is not having any reference.
- It can have nested block in it which can be named or anonymous. It can also be nested to any blocks.
- These blocks can have all three sections of the block, in which execution section is mandatory, the other two sections are optional.
Named blocks:
Named blocks are having a specific and unique name for them. They are stored as the database objects in the server. Since they are available as database objects, they can be referred to or used as long as it is present in the server. The compilation process for named blocks happens separately while creating them as a database objects.
Below are few more characteristics of Named blocks.
- These blocks can be called from other blocks.
- The block structure is same as an anonymous block, except it will never start with the keyword 'DECLARE'. Instead, it will start with the keyword 'CREATE' which instruct the compiler to create it as a database object.
- These blocks can be nested within other blocks. It can also contain nested blocks.
- Named blocks are basically of two types:
- Procedure
- Function